v0.7.0 · Open Source · MIT Licensed · 
Turn idle Macs into an
AI compute fleet
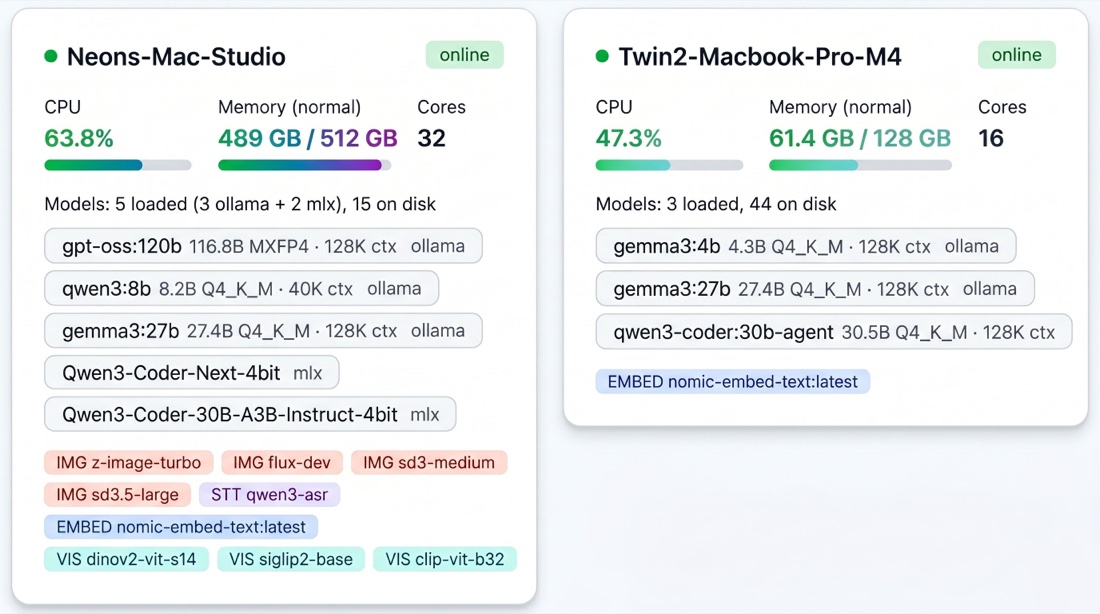
Your spare Mac has 36GB of RAM doing nothing. Run DeepSeek-R1 70B on the Studio, FLUX image gen on the MacBook, Qwen3-ASR transcription on the Mini, all through one endpoint. Fix that.
# Install (or upgrade to v0.7.0), works on macOS, Linux, and Windows
pip install ollama-herd --upgrade
# macOS/Linux also: brew tap geeks-accelerator/ollama-herd && brew install ollama-herd
# Windows: pip works; uv is the fast path (curl -sSf https://astral.sh/uv/install.sh | sh, then `uv tool install ollama-herd`)
# Start the router (on your most powerful machine)
herd
# On each device in your fleet
herd-node
# That's it. Nodes auto-discover the router via mDNS.